NBA球员信息盘点(数据分析)
使用了python的自动化框架selenium进行动态爬取,Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
本次爬取的网址是腾讯网的NBA栏目,爬取的内容是NBA球员的比赛信息以及热点新闻,爬取完成后将数据保存到csv文件中以便分析读取,后续会通过生成图表图形的方式来展示具体爬取的内容。
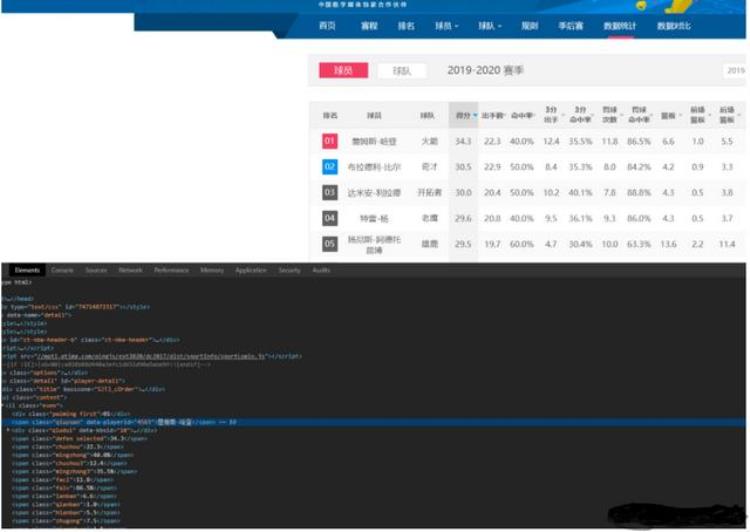
1.2爬虫的步骤爬取的步骤为:确定爬取的内容、对主页面解析、子页面的获取、子页面的解析、数据的保存。我爬取的网站暂未发现反爬虫机制,所以本次不做反爬虫措施。先找到要爬取的页面,通过解析主页面的标签找到进入子页面的链接,然后在子页面找到要爬取的信息对应的标签分析页面:
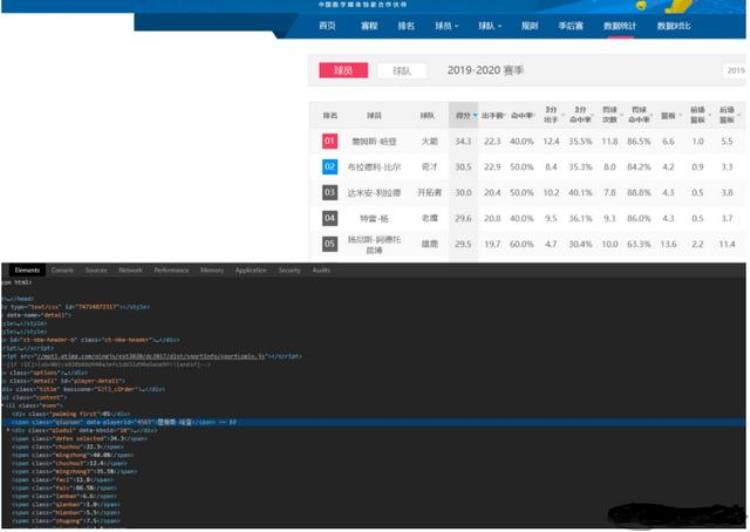
可以看到要爬取的信息都会在对应的标签或者对应的class下,因此我们可以根据选择进行爬取。
获取页面所用的代码:
from selenium import webdriverbrowser = webdriver.Chrome('D:/chromedriver.exe')browser.get('https://sports.qq.com/nba/')2.数据存储2.1写入csv爬取到所需的数据之后,需要对数据进行处理,本文使用了写入csv和写入txt的方法来保存数据。
with open("NBA.csv","w",newline="") as csvfile: writer = csv.writer(csvfile) writer.writerow(["排名","球员","球队","得分","出手数","命中率","3分出手","3分命中率","罚球次数","罚球命中率","篮板","前场篮板","后场篮板","助攻","抢断","盖帽","失误","犯规","场次","上场时间"])由于第一次写入的是每一列的列名,所以使用了两次with open的方法,第二次开始循环写入每一行的信息。
#要爬取的内容 input4_players=browser4.find_element_by_class_name('content') input4_players2=input4_players.find_elements_by_css_selector('li') for j in range(len(input4_players2)): paiming=input4_players2[j].find_element_by_class_name('paiming').text qiuyuan=input4_players2[j].find_element_by_class_name('qiuyuan').text qiudui=input4_players2[j].find_element_by_class_name('qiudui').text defen=input4_players2[j].find_element_by_class_name('defen').text chushou=input4_players2[j].find_element_by_class_name('chushou').text mingzhong=input4_players2[j].find_element_by_class_name('mingzhong').text chushou3=input4_players2[j].find_element_by_class_name('chushou3').text mingzhong3=input4_players2[j].find_element_by_class_name('mingzhong3').text faci=input4_players2[j].find_element_by_class_name('faci').text falv=input4_players2[j].find_element_by_class_name('falv').text lanban=input4_players2[j].find_element_by_class_name('lanban').text qlanban=input4_players2[j].find_element_by_class_name('qlanban').text hlanban=input4_players2[j].find_element_by_class_name('hlanban').text zhugong=input4_players2[j].find_element_by_class_name('zhugong').text qiangduan=input4_players2[j].find_element_by_class_name('qiangduan').text gaimao=input4_players2[j].find_element_by_class_name('gaimao').text shiwu=input4_players2[j].find_element_by_class_name('shiwu').text fangui=input4_players2[j].find_element_by_class_name('fangui').text changci=input4_players2[j].find_element_by_class_name('changci').text shangchang=input4_players2[j].find_element_by_class_name('shangchang').text with open("NBA.csv","a ",newline="") as csvfile: writer = csv.writer(csvfile) writer.writerow([paiming,qiuyuan,qiudui,defen,chushou,mingzhong,chushou3,mingzhong3,faci,falv,lanban,qlanban,hlanban,zhugong,qiangduan,gaimao,shiwu,fangui,changci,shangchang])2.2写入txttxt文件用于保存爬取到的NBA热点新闻,以便后续生成词云。
#写入txt文件 with open("NBA_news.txt", "a ", encoding='utf-8') as f: f.write(input3_news_title.text) for j in range(len(input3_news2)): f.write(input3_news2[j].text)3.数据分析及可视化3.1NBA球员身高区间对NBA球员的身高区间进行分析,让我们更直观了解到NBA球员的身高第一步先对NBA球员的身高区间进行划分NBA球员基础信息如下:
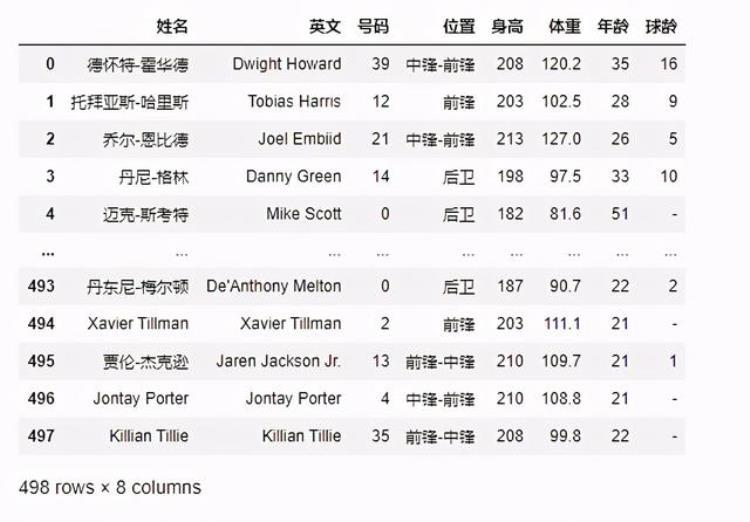
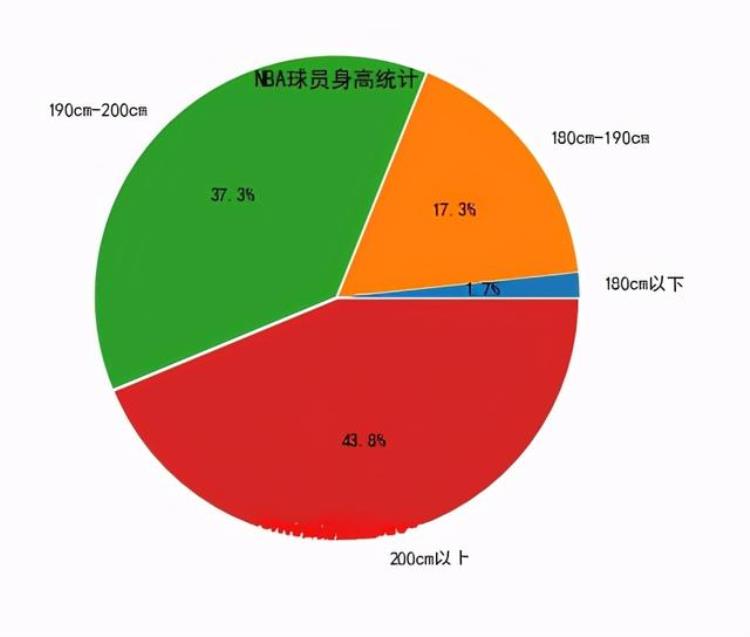
将身高划分为180(cm)以下、180-190(cm)、190-200(cm)、200(cm)以上四个区间
import pandas as pddf = pd.read_csv(r'C:UsersDesktopNBA_PLAYERS_HEIGHT.csv')#身高小于180cm的球员总数len(df[df['身高']180 ) & (df['身高'] 190 ) & (df['身高'] = 200])使用matplotlib库进行可视化:
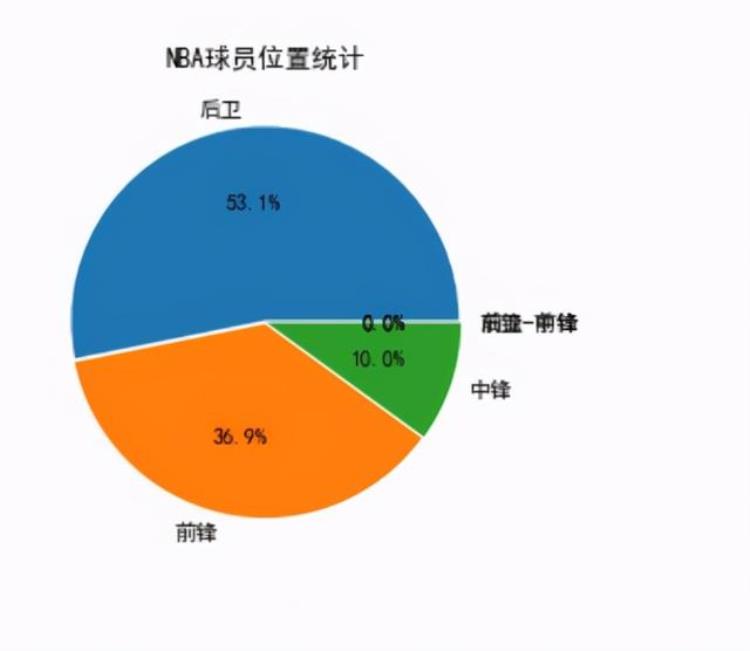
 3.2NBA球员场上位置分布
3.2NBA球员场上位置分布
对NBA球员在场上的位置分布进行分析分别有后卫、前锋、中锋、后卫-前锋、前锋-中锋五个位置使用matplotlib库进行可视化:
 3.3NBA球员得分分析
3.3NBA球员得分分析
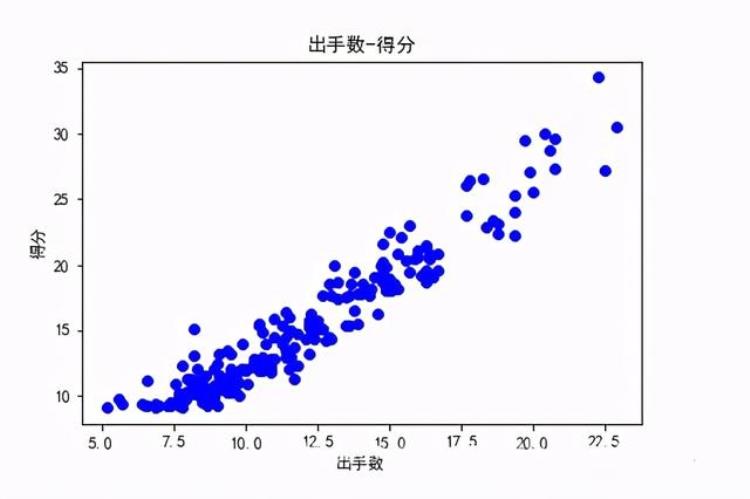
观察NBA球员得分与出手数的关系
import numpy as np from matplotlib import pyplot as plt import pandas as pddf = pd.read_csv(r'C:UserspzjDesktopNBA_PLAYERS.csv')x = df['得分']y = df['出手数']plt.title("得分-出手数") plt.xlabel("得分") plt.ylabel("出手数") plt.plot(x,y,"ob") plt.savefig(r'C:UserspzjDesktopNBAPICS3.jpg')plt.show()使用散点图直观显示:
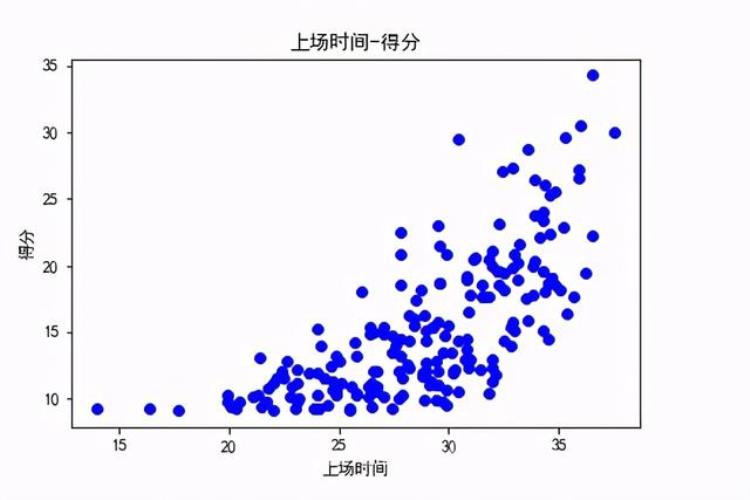
观察NBA球员得分与上场时间的关系:使用散点图直观显示:
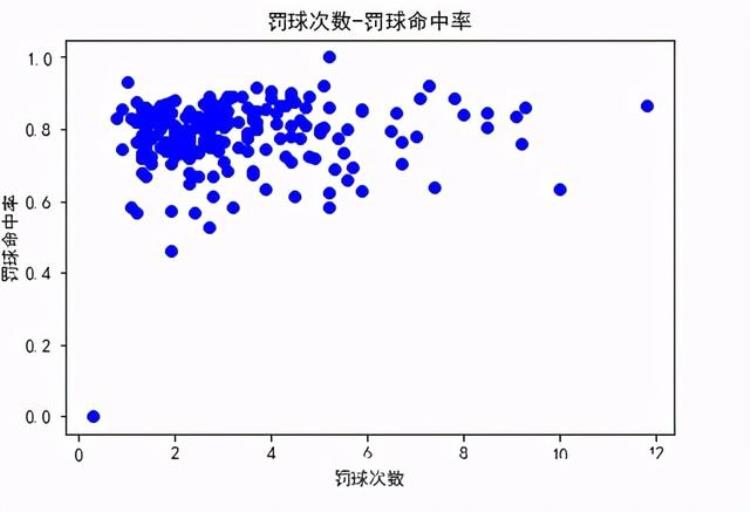
观察NBA球员罚球数与罚球命中率的关系:
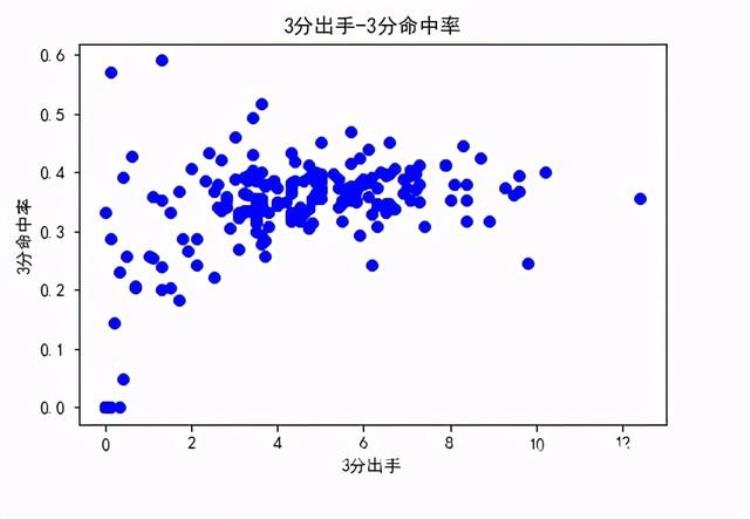
观察NBA球员三分出手数和三分命中率的关系:
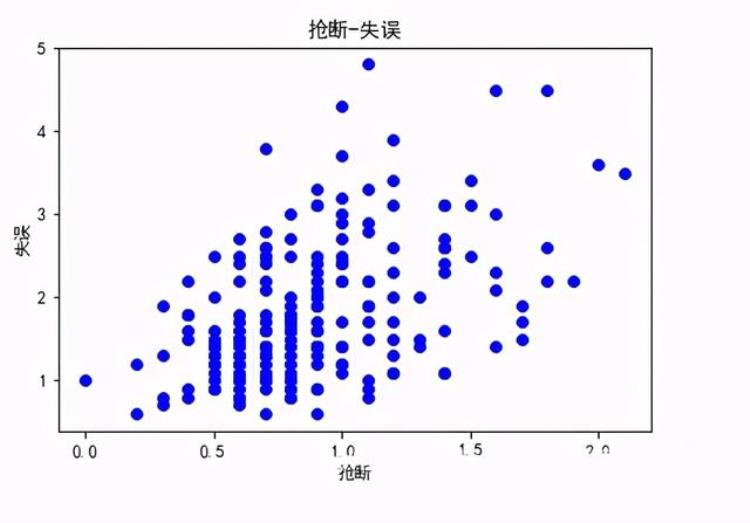
观察NBA球员抢断数与失误数的关系:
 3.4计算上场时间与场次
3.4计算上场时间与场次
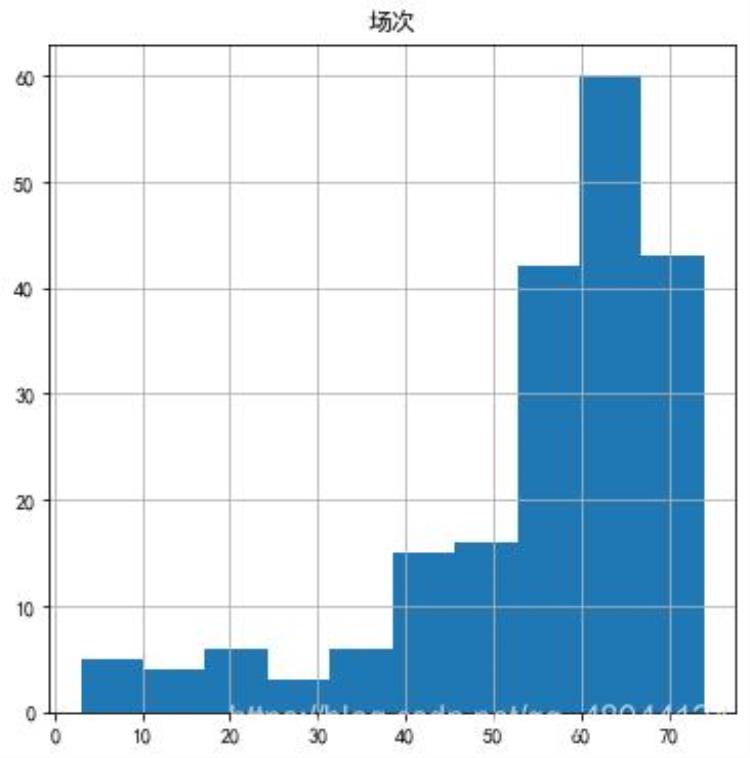
图1 场次
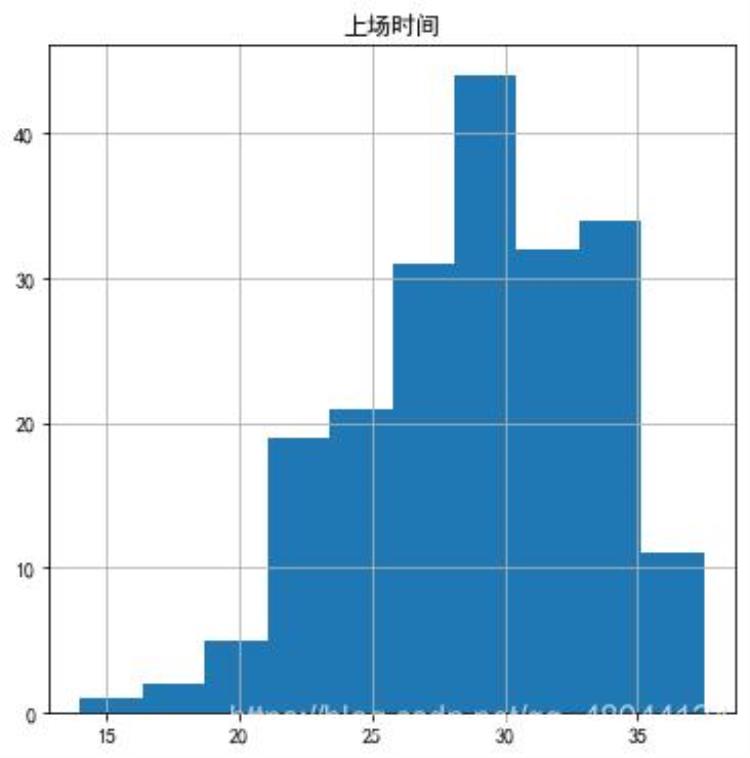
图2 上场时间
3.5NBA热点新闻爬取NBA新闻的源码:
#爬取NBA栏目新闻板块def NBA_NEWS():#在首页中找到NBA栏目新闻板块所在位置(在class为'nav-a=tl'的列表中第三个) input_news= browser.find_elements_by_class_name('nav-a-tl')[3] print(input_news.text) browser2=webdriver.Chrome('D:/chromedriver.exe')#通过刚找到的新闻板块位置找到进入新闻板块首页的链接 browser2.get(input_news.get_attribute('href'))#在新闻板块首页中找到进入具体每一条新闻所对应的class(一个列表) input2_news= browser2.find_elements_by_class_name('picture') browser3=webdriver.Chrome('D:/chromedriver.exe') #爬取所有新闻 for i in range(len(input2_news)): browser3.get(input2_news[i].get_attribute('href')) #获取新闻内容 input3_news=browser3.find_element_by_class_name('content-article') input3_news2=input3_news.find_elements_by_css_selector('p') #获取新闻标题 input3_news_title=browser3.find_element_by_class_name('LEFT') #写入txt文件 with open("NBA_news.txt", "a ", encoding='utf-8') as f: f.write(input3_news_title.text) for j in range(len(input3_news2)): f.write(input3_news2[j].text) print(input3_news_title.text) browser3.close() browser2.close()爬取成功后保存在一个txt文件中txt文件:

通过词云将关键词整合出来

感谢阅读!!!
多说一句,很多人学Python过程中会遇到各种烦恼问题,没有人解答容易放弃。小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并在后台私信小编:“01”即可领取。
特别声明:所有资讯或言论仅代表发布者个人意见,乐多体育仅提供发布平台,信息内容请自行判断。
-
 文章目录NBA球员信息盘点(数据分析)1.数据抓取1.1使用工具及爬取内容介绍1.2爬虫的步骤2.数据存储2.1写入csv2.2写入txt3.数据分析及可视化3... (查看全文)2022-11-28 | 阅读:170次
文章目录NBA球员信息盘点(数据分析)1.数据抓取1.1使用工具及爬取内容介绍1.2爬虫的步骤2.数据存储2.1写入csv2.2写入txt3.数据分析及可视化3... (查看全文)2022-11-28 | 阅读:170次









- 特别声明:本站所有直播和视频均来自互联网,本站不从事任何经营业务,仅为体育爱好者提供免费赛事数据服务。备案号:苏ICP备2020049342号广告合作@huzhan6688:QQ:95498723